02little_endians¶
1. CNOT门分解¶
CNOT 门的矩阵形式为:
考虑将其分解成 2 维矩阵,来了解 CNOT 的作用方式,i.e.
在这里,P 作用在前面的 qubit,I / X 作用在后面的 qubit。其中,
注意 !
其效果就是:当第一个 qubit 是 \(\ket{0}\) 时,I 矩阵不改变后面的 qubit;当第一个 qubit 是 \(\ket{1}\) 时,X 矩阵就会反转后面的 qubit。现在,将 CNOT 矩阵分别作用在 \(\ket{01}\) 态和 \(\ket{10}\) 态,
以上是正常的公式计算的结果,然而在使用qiskit或者其他编程语言中,却遇到了不同的情况。
2. What happened in qiskit¶
在 qiskit 中有 UnitaryGate 工具可以将矩阵转化为量子门,如:
from qiskit import QuantumCircuit
from qiskit.extensions import UnitaryGate
matrix1 = [[1, 0, 0, 0],
[0, 1, 0, 0],
[0, 0, 0, 1],
[0, 0, 1, 0]]
gatecx = UnitaryGate(matrix1)
circuit = QuantumCircuit(2,2)
circuit.x(0)
circuit.append(gatecx,[0,1])
circuit.draw('mpl',scale=0.6)
我们预计上述代码的结果应该是 \(\ket{11}\),但结果出乎意料:
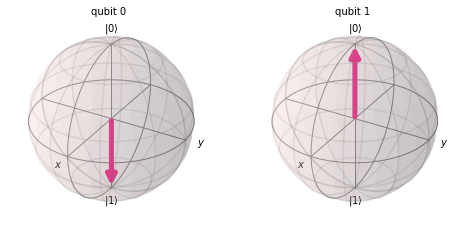
原因是在 qiskit 中,qubit 编码方式为 “Little endians”,叫做 “小端编码”,或者 “末端编码”。即,倒序排列 \(\ket{q3q2q1q0}\)。
因此,在做计算时矩阵也是倒序作用 \(B \otimes A\),表示 A 和 B 分别作用在 \(q0\) 和 \(q1\) 上。据此分析,构造 CNOT 的思路应该是:
所以在qiskit中,构造CNOT门应该使用的矩阵是:
3. 什么是Little endians¶
比如一个 16 进制的整数 “0x1234”,其二进制是 “0001 0010 0011 0100”,左边是高字节序,右边是低字节序。
有时候CPU会一次读或者存多位数据,假设一次处理 8bit,也就是 1byte,那么下面的方式是明显符合我们逻辑的:
低地址 → → → 高地址
| 12 | - - - - - - | 34 |
这种方式被称作 Big endians,低地址放高字节序。
而当前流行的Intel和AMD大部分处理器都是采用了 Little endians,也就是低地址放低字节序:
低地址 → → → 高地址
| 34 | - - - - - - | 12 |\
目前我并没有找到什么特殊的原因 “非这样做不可”。
但是需要注意,如果CPU读取方式和内存存放的方式不同,那么CPU在读取之后还需要进行一次重排,这会大大增加计算开销。
另外网络传输数据也会受到该影响,降低传输效率。